Our team is passionate about Realtime Business Platforms, especially ones we help build using our standard framework of Cassandra, Spark, and Kafka. We built this site because we needed a site like it. One place to know what’s going in the Apache Cassandra community from all the different viewpoints. Since there are now different commercially backed variants of Apache Cassandra such as Datastax, DDACS, Scylla, Yugabyte, Elassandra, and Microsoft’s CosmosDB, we felt that out of self-interest none of those folks were going to come together to make a resource like the one we craved.
Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra. We want to bring the Cassandra community, no matter what variant they use, together.
v0.1 – Awesome Cassandra
https://anant.github.io/awesome-cassandra
The earliest version of Cassandra.Link is still up at Github and powers the resources section of the Cassandra.Link site.
If you want, you can help curate this Table of Content style knowledge base by doing a pull-request on Github.com/Anant/awesome-cassandra. It currently has Cassandra articles tools etc. organized in a table of contents.

v.0.2 – Leaves.Topic / Leaves.Reader / Cassandra
We tried another iteration of organizing knowledge with an Open Source tool called Wallabag (a clone of the popular Pocket app by the Mozilla Foundation). We ended up organizing and tagging 600+ links. The Wallabag interface is primarily for a single user so we used the API to build a Next.JS and an Angular interface to this. This is still in progress and may make its way back to the Cassandra.Link site. Right now the Leaves interface includes 10k+ links from across the different technology and business topics we are interested in.


v.0.3 – Leaves.Search / Cassandra
All of the links in Wallabag were then indexed into Apache Solr powered by SearchStax and we used our Appleseed Search Web User components built with AngularJS to quickly prototype this Search Interface. These links are analyzed by IBM’s Watson Natural Language Understanding ( formerly known as AlchemyLanguageAPI ) and tagged/taxonomized auto-magically.

v.0.4 – Cassandra.Link
We learned a great deal from using these tools and getting feedback from different folks. We learned from using our different versions and decided to use a statically generated site published on Netlify, a CDN. There were many tools out there but we decided on using Gatsby because it could get data from different sources and unify the intermediary format as GraphQL and it used React as it’s templating engine. We’d used React and Next.js, so it was a no-brainer.

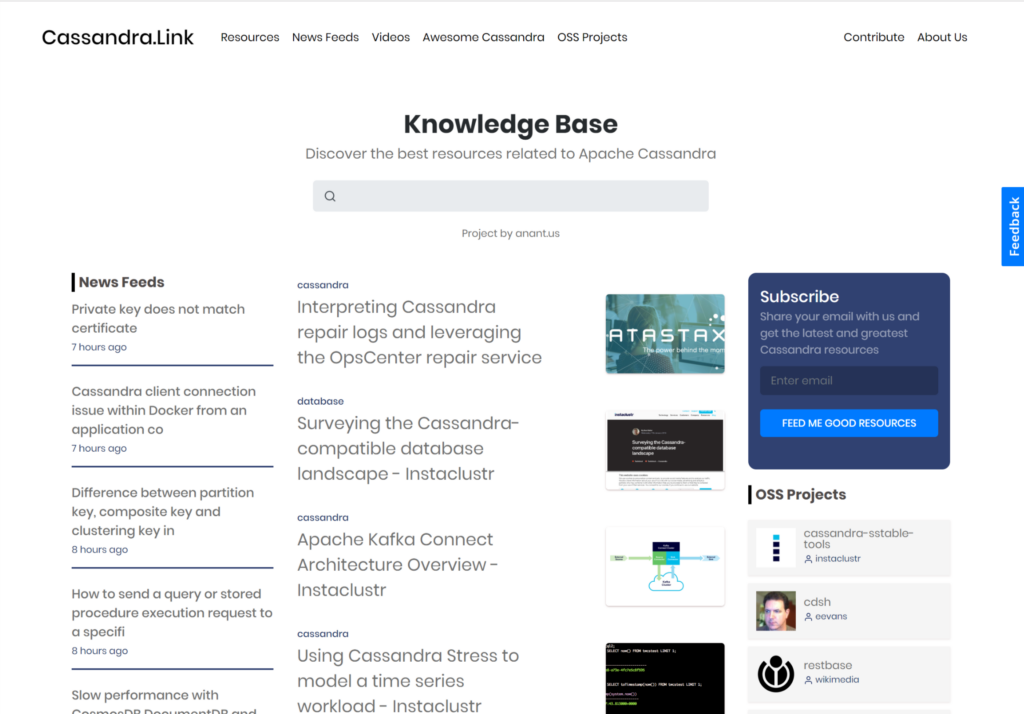
The site currently has the following features and we continue to get ideas from our users, team members, and clients.
- Feeds: 15 RSS Feeds including blogs and Stackoverflow tags, more to come related to Apache Cassandra, Datastax, Scylla, Yugabyte, Elassandra, Microsoft CosmosDB.
- Articles, Videos, Open Source Projects: All of the links we continue to organize in our Wallabag tagged with Cassandra, and more every day.
- Search: Algolia Powered Search. We’re going to rethink this. We like using SearchStax Solr because it’s “Apache Solr” and we know Solr well. Algolia is super fast though but not as powerful. We’ll see.
- Email List: Mailing List will be used to send digests once we have a critical mass of users with some feedback on the current iteration.
What’s next? We have a lot of homework to do to continue refining the Cassandra.Link user-interface and move towards easier ways for people to collaborate on the content.
We’re not trying to make it another blog/aggregation, another wiki, another directory, or forum. Those things already exist. Our goal is to bring it together in a way that makes sense and make it usable. There’s so much crap out there on the internet, we need to ascend from the Age of Information to the Age of Knowledge.

