By Lili Kazemi, General Counsel & AI Policy Leader, Anant Corporation
🏜️ What This Series Covers: The Gold Rush for AI Ownership
🤠 Welcome to the Wild West of AI Ownership.
AI is rewriting the rules of creativity, commerce, and control—but no one handed out a map. Lawmakers, litigators, and technologists are scrambling to draw boundaries around a technology that doesn’t follow old fences. The result? A legal frontier as unsettled as it is explosive.
This four-part series explores the emerging law and policy landscape for large language models (LLMs)—and what’s at stake for anyone who builds, uses, or is copied by AI.
Part I (you’re here) breaks down the copyright rules for training data, the Meta and Anthropic rulings, and how courts are beginning to draw the first lines around what’s fair—and what’s not.
Part IItackles the Napster problem: why analogies to music piracy fall short in the world of LLMs, and why AI synthesis requires a new legal lens.
Part IIIzooms in on output liability—when models mimic protected works in style, voice, or structure—and whether that’s enough to trigger copyright infringement.
Part IV shifts from law to money: exploring how AI systems are being valued, taxed, and priced across jurisdictions, and what this means for global IP and transfer pricing regimes.
Across all four parts, the goal isn’t to pick sides—it’s to map the terrain. In a world where AI systems learn from everything but are owned by no one, understanding what’s owed (and to whom) is the first step toward a smarter, safer digital economy.
📚 Where Are We in the AI Evolution?
The legal battles playing out in U.S. courts—from NYT v. OpenAI to Kadrey v. Meta—are largely focused on generative AI, the second wave of a much broader technological transformation. According to NVIDIA CEO Jensen Huang, we’re currently in the third phase of a four-stage AI roadmap that’s rapidly redefining what machines can perceive, generate, and do in the physical world.
Four Stages of AI (per NIVIDIA’s Jensen Huang, via David Timis): 1️⃣ Perception AI (2012–2018): Vision and speech recognition 2️⃣ Generative AI (2020–2024): Content creation, text-to-image/video 3️⃣ Reasoning AI (began 2024): Logic, problem-solving, deeper research 4️⃣ Physical AI (expected 2026): Robotics, common sense, real-world awareness
The copyright lawsuits dominating headlines today—book training, output mimicry, fair use—are grappling with the rules of Phase 2. But industry leaders, courts, and policymakers will soon face new challenges as we transition to reasoning and physical AI, where model behavior becomes less about content generation and more about autonomous decision-making.
That’s where the governance gaps will really start to show.
🚨 This Is an Even Bigger Problem
In-house counsel at tech companies can agree: there’s a major governance gap when it comes to AI. The EU AI Act has taken a first stab at closing that gap, introducing a tiered risk framework, mandatory disclosures, and requirements for foundation model providers. But for U.S.-based companies, especially those navigating cross-border development and deployment, there’s still no comprehensive governance structure—and no clear legal answer to what’s fair, what’s protected, or what’s owed.
Across jurisdictions, foundational questions about AI ownership and accountability remain unanswered:
What kinds of data can legally be used for training?
Do creators need to opt in—or opt out?
Can we trace, license, or restrict what a model “remembers”?
In the absence of clear rules, litigation has become the default mechanism for drawing boundaries. Cases like Bartz v. Anthropic, Kadrey v. Meta, and NYT v. OpenAI are starting to shape the conversation—but the results so far have been fragmented, narrow, and inconclusive.
These aren’t just edge cases. They’re signs of deeper legal fractures in what is fast becoming a trillion-dollar AI economy. Just this week, Anthropic cut off OpenAI’s access to its Claude model, alleging violations of commercial terms—specifically, a ban on using Claude outputs to train competing models.
This wasn’t just a contractual squabble. It’s a sign that in the absence of clear legal rules, companies are enforcing boundaries through private agreements—and increasingly, through retaliation. As LLMs become strategic infrastructure, questions around model use, benchmarking, and API access are triggering high-stakes showdowns between major players.
In an industry where the product is knowledge and access is leverage, legal ambiguity isn’t a speed bump—it’s a fault line. And just like in the Wild West, when the law lags behind the frontier, what gets built depends on who gets there first—and who draws the boundaries after the dust settles.
⚖️ The Legal Question: What Guardrails Should Exist on ‘AI Training’?
Copyright law was designed around observable, one-to-one copying. The framework is built on questions like:
Ownership – Is the original work fixed in a tangible medium?
Copying – Did the defendant duplicate or incorporate that work?
Substantial Similarity – Is the copied content meaningful, not trivial?
Market Harm – Has the use caused—or could it cause—economic loss?
From there, courts apply the fair use test:
Was the use transformative?
Was the source factual or creative?
Was only a portion used?
Did the use affect the market?
But the legal framework for copyright was built around observable duplication—not for systems that learn from patterns, absorb massive datasets, and generate original-seeming outputs through probabilistic inference.
They don’t map cleanly onto scenarios where:
A model trains on 180,000 pirated books from a dataset like Books3
That information is absorbed into model weights
The output reflects learned patterns—but doesn’t replicate any one input
LLMs are trained to infer, not to reproduce. Their power lies in generalization. But that doesn’t mean the rights of creators weren’t implicated along the way. When a model can produce outputs shaped by thousands of copyrighted works—without copying any single one—our legal tools struggle to define what was taken, and what was simply learned.
📚 What the Models Were Actually Trained On
It’s become common shorthand to say that large language models were “trained on the internet.” But that framing is too vague—and increasingly unhelpful. It glosses over the critical fact that the internet is not a rights-free zone. It’s a patchwork of copyrighted materials, open licenses, user agreements, and digital fences—some visible, many not.
In reality, these models were trained on what was available—not necessarily what was licensed. That includes pirated books, scraped news sites, academic journals, proprietary codebases, and paywalled journalism. Datasets like Books3, Library Genesis, and Common Crawl became go-to resources, even though they contained thousands of copyrighted works used without consent. Even platforms like GitHub and Wikipedia, which appear “open,” come with licensing terms and use restrictions that were often ignored or sidestepped.
The result? The foundation of many commercial AI systems was built on a legally unstable mix of content—with unclear provenance, murky permissions, and a rapidly growing litigation risk.
📚 Why Prompting Matters in the Lawsuits Over ‘Copying’
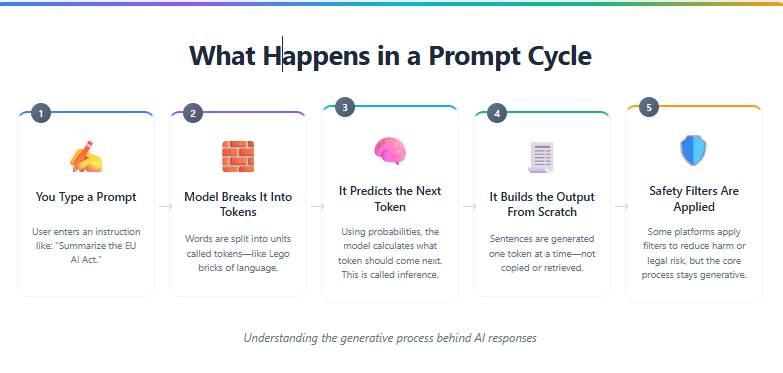
In many of the AI copyright lawsuits, plaintiffs claim that companies copied books, articles, or code to train their models. But it’s not always clear what is being copied—or when. A critical distinction lies in how generative AI produces responses: the output you see isn’t simply pulled from a source like a search result. It’s the product of a layered system that includes a system prompt (set by the developer), a user prompt (what you type), and prompt engineering (how the prompt is crafted to elicit better results).
Even taking the simple example of a user prompt in an AI model, a lot happens from when you type to when you get your response. It just doesn’t seem that way because AI models like GPT-4, Claude, and Gemini can generate full, polished responses in just a few seconds—processing words at speeds of 30 to 70 tokens per second, far faster than any human could think or type
This flowchart illustrates the often-invisible chain of events between AI training “inputs” and the final AI-generated output—spanning data ingestion, model training, inference, and filtering layers. It’s a visual shorthand for the legal and technical black box at the heart of generative AI debates: who contributes value, who controls the process, and who gets paid.
For a deeper dive into the AI value chain—and how economic value can disappear when workers are replaced by a “ghost workforce” of AI—see: When AI Works, Who Gets Paid?
What seems like a simple question—“Summarize this”—actually triggers a highly complex series of probabilistic calculations shaped by thousands of prior inputs and learned representations. The output may look polished and deliberate, but beneath the surface is a layered, opaque system of inference, approximation, and pattern-matching.
This is why regulating or taxing AI based on surface-level outputs alone misses the deeper value chain. It’s not just about what a model says—it’s about how it produces that response, and the inputs and infrastructure that made it possible.
🏛 The Great Copyright Roundup: Content Creators Push Back, Courts Push Harder
Two key federal cases—Bartz v. Anthropic and Kadrey v. Meta—are helping to define the boundaries of fair use in the context of AI training, offering early but diverging guidance on how courts view the use of copyrighted books to train large language models.
Case
Fair Use Ruling (Inputs)
Pirated Books / Acquisition
Output Liability
Market Harm
Key Judicial Commentary
Bartz v. Anthropic Judge William Alsup Order on Fair Use June 23, 2025
Training on lawfully purchased books held to be “quintessentially transformative” and protected by fair use. Digitizing physical copies for internal use also upheld because only action by Anthropic was to replace print copies t had purchase with searchable digital copies, without creating new works or redistributing existing copies.
Fair use denied for building a general-purpose research library using pirated books. “[P]irating copies to build a research library…was its own use—and not a transformative one.”
No infringing outputs were alleged. Training on lawfully acquired books was held to be fair use; however, the court denied fair use for Anthropic’s storage and use of pirated books, allowing a class action to proceed for works scraped from shadow libraries.
Not addressed. The decision turned on inputs and storage, not economic impact. A market for licensing books for AI training “is not one the Copyright Act entitles Authors to exploit.”
“Here, if the outputs seen by users had been infringing, Authors would have a different case. And, if the outputs were ever to become infringing, Authors could bring such a case. But that is not this case”
On the concern of saturating the market with AI-derived works competing with original works, judge dismissed this argument, comparing this complaint to complaining that “training schoolchildren to write well would result in an explosion of competing works”
Kadrey v. Meta Judge Vince Chhabria June 25, 2025 Order granting partial summary judgment to Meta on fair use defense
Inputs treated as transformative, but court stressed that this alone doesn’t establish fair use.
Use of books from shadow libraries did not preclude fair use in this case, though may matter in others.
Court rejected blanket allegation that “every output of LLaMA language models is an infringing derivative work“. Plaintiffs’ vicarious infringement claim failed because they did not allege any outputs containing protected expression. “Without [] an infringing output, there can be no vicarious infringement.” Meta successful in arguing that AI isn’t trying to be a book; it’s a “quintessentially transformative” product that learns from books to do something entirely different.
The court rejected the claim that Meta’s use of copyrighted material harmed authors by undercutting a potential market for licensing AI training. But it found “far more promising” a third argument: that LLMs could saturate the market by generating works similar in style or subject matter, creating indirect competition with the originals.
Despite acknowledging the risk, the judge ultimately ruled that the plaintiff’s argument “does not move the needle”—not because the claim lacked merit, but because they hadn’t clearly made that argument during the case. Meta granted summary judgment on fair use defense.
“[I]n the grand scheme of things, the consequences of this ruling are limited…[T]his decision does not stand for the proposition that Meta’s use is lawful—only that these plaintiffs made the wrong arguments and failed to develop a record in support of the right one.”
Judge warned of future risk: “Generative AI has the potential to flood the market.” Took issue with Judge Alsup’s schoolchildren comparison, commenting that “This inapt analogy is not a basis for blowing off the most important factor in the fair use analysis”
Judges Alsup and Chhabria took notably different approaches to fair use in the context of AI training. Alsup framed Anthropic’s use of purchased print books as “exceedingly transformative” and emphasized that no infringing outputs were shown, likening LLM training to teaching schoolchildren to write—a use he deemed permissible under copyright law. In contrast, Chhabria criticized this analogy as “inapt,” stressing that using books to train a commercial AI product capable of mass-generating substitute works posed a far greater threat to the market for original writing. While both judges acknowledged the transformative nature of LLMs, Chhabria was more attuned to the potential for market dilution and the broader economic harm to authors, ultimately finding that plaintiffs in the Meta case failed not on the merits, but because they didn’t properly argue this market impact in court.
Two rulings handed down within 48 hours—by two federal judges in the same district—underscore just how unsettled the legal terrain remains when it comes to AI and copyright. Even in the heart of Silicon Valley, the boundaries of fair use are being drawn in real time.
For another comparison chart written by one of the renown copyright academics, check out Professor Lee’s twitter post here:
Are you confused about the fair use decisions in Anthropic and Meta cases that came out this week? Created a Table to highlight the differences and agreement. 2 big differences: (1) pirated books treatment and (2) new theory of copyright market dilution. Other parts more aligned pic.twitter.com/hSVc4Azk6f
Common sense application of IP rules to AI.” “AI should be able to learn the way people do — by reading, processing, and building knowledge.”
–President Donald J. Trump, speaking at the National AI Summit
TheAI Action Plan released by the Trump administration in July 2025 avoided taking a formal stance on copyright. But in off-script remarks at the National AI Summit, President Trump made his views clear: AI should “learn the way people do — by reading, processing, and building knowledge.” He called for the “common sense application of IP rules to AI” and questioned whether licensing every book was necessary for training.
While the plan itself focuses more on innovation and competitiveness than copyright, Trump’s comments signaled strong support for Big Tech’s interpretation of fair use in AI training.
The Senate is not necessarily on the same page—during a July 16, 2025 Judiciary subcommittee hearing, lawmakers and authors voiced sharp criticism of AI companies for training on copyrighted books without consent. Authors like David Baldacci described the experience as “someone backing up a truck to my imagination and stealing everything I’d ever created,” while Senator Josh Hawley called it “the largest intellectual property theft in American history.” The hearing underscored growing bipartisan support for legislative action that goes beyond fair use protections.
The Domino Effect: When Legal Uncertainty Spreads
The copyright crisis isn’t contained to courtrooms. Legal uncertainty creates a cascade of risks across the entire AI ecosystem:
🎯 Training Data Sources → Restrictions on data access force models to use lower-quality or legally questionable datasets
⚡ Model Development → Uncertainty about fair use makes it harder to plan training pipelines and evaluate legal risk
🔧 Infrastructure Partnerships → Cloud providers and chip manufacturers face indirect liability concerns
📊 Market Confidence → Investors pull back when fundamental legal questions remain unresolved
🚀 Innovation Pipeline → Startups struggle to secure funding without clear IP frameworks
🌍 Global Competition → Other jurisdictions gain advantage with clearer regulatory frameworks
Each fallen domino makes the next more likely to tip. The solution isn’t to stop innovation—it’s to build stable legal foundations that let all players plan for the future.
Final Thoughts
In this digital Wild West, fortunes are being made and lost daily. But eventually, every frontier needs laws. The question is whether they’ll come from courts, Congress, or the companies themselves.
The companies that thrive will be those that recognize good governance isn’t a constraint on innovation—it’s the foundation that makes sustainable innovation possible.
Essential Reading on AI Copyright
For deeper analysis on the evolving legal landscape:
Next: Part II examines why comparing AI copyright to Napster misses the mark—and reveals how two landmark federal rulings are charting different paths through the legal wilderness
Lili Kazemi is General Counsel and AI Policy Leader at Anant Corporation, where she advises on the intersection of global law, tax, and emerging technology. She brings over 20 years of combined experience from leading roles in Big Law and Big Four firms, with a deep background in international tax, regulatory strategy, and cross-border legal frameworks. Lili is also the founder of DAOFitLife, a wellness and performance platform for high-achieving professionals navigating demanding careers.
🔍 Discover What We’re All About
At Anant, we help forward-thinking teams unlock the power of AI—safely, strategically, and at scale. From legal to finance, our experts guide you in building workflows that act, automate, and aggregate—without losing the human edge. Let’s turn emerging tech into your next competitive advantage.
👇 Click on the image to subscribe to our weekly AI newsletter: