
In Data Engineer’s Lunch #89: Machine Learning Orchestration with Airflow, we discussed using Apache Airflow to manage and schedule machine learning tasks. The live recording of the Data Engineer’s Lunch, which includes a more in-depth discussion, is also embedded below in case you were not able to attend live. If you would like to attend a Data Engineer’s Lunch live, it is hosted every Monday at noon EST. Register here now!
Airflow Overview
Apache Airflow is an open-source tool for scheduling and automating workflows. Airflow allows you to define workflows in Python, with tasks defined as Python functions that can include Operators for all sorts of external tools. This makes it easy to automate repeated processes and define dependencies between tasks, creating directed-acyclic-graphs of tasks that can be scheduled using cron syntax or frequency tasks. Airflow also features a user-friendly UI for monitoring task progress and viewing logs, giving you greater control over your data pipeline.
ML Pipelines
Machine learning processes typically involve breaking down the task into small, repeatable chunks that can be executed efficiently. Many machine learning tasks are batch processing jobs that operate on blocks of data at a time. Even predictions can be processed in batches if results are not time-sensitive. This batch processing structure aligns well with Airflow’s capabilities to schedule, automate, and manage task dependencies. Airflow’s directed-acyclic-graphs of tasks can be used to organize machine learning workflows into smaller, more manageable units, making it easier to monitor and troubleshoot the pipeline. By leveraging Airflow’s automation and task management features, machine learning engineers can more easily build and maintain scalable, efficient, and accurate models.
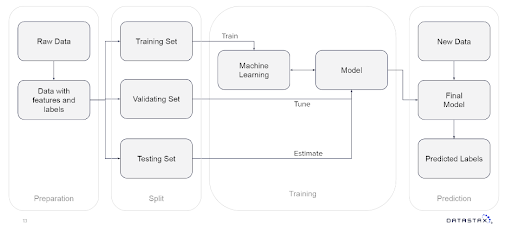
Data Preparation
The first step in training a machine learning model is to prepare your data. This involves cleaning, formatting, and pre-processing your dataset. The goal is to create a dataset that is well-structured and ready for analysis. This can include removing missing values, encoding categorical variables, and normalizing numerical features. This breaks down to a set of ETL processes of the type that are easily manageable via Airflow. It is still preferable to keep stuff involving actual data processing separate from the dag code. Airflow Scheduler and/or worker processes can get bogged down when asked to do actual data processing.
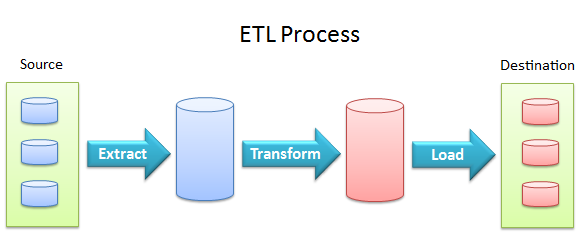
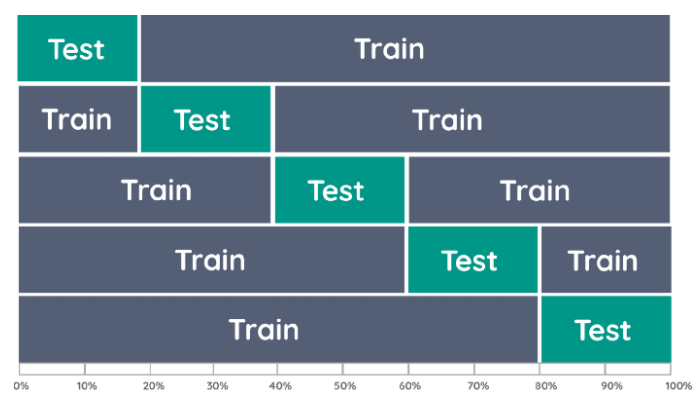
Train / Test Split
Once the data is ready, the next step is to split it into training and testing sets. The training set is used to train the machine learning model, while the testing set is used to evaluate its performance. This split ensures that the model is not overfitting or memorizing the training data and can generalize well to unseen data. The splitting process is dependent on the data that comes in, making it easy to slot into a data ingestion DAG in a way that reflects that dependency.
Model Training
In this step, the machine learning model is trained on the training dataset. This involves selecting a suitable algorithm, configuring its hyperparameters, and feeding the training data into the model. The model learns to make predictions by adjusting its weights and biases to minimize the difference between its predictions and the actual values.
For most machine learning algorithms, model training is a standard batch process, as the model must be trained on all the available data before it can be used. This step is also closely tied to the storage of the model. With permanent model methods, the trained model is stored in a central location, and new prediction requests use the most recent version of the model available.
There are a variety of formats for saving machine learning models to disk, with Python objects being easily savable via pickling. Some models may even be small enough to be fully stored in memory.
Transient model methods, on the other hand, have each request trigger the training of a new model, which is used to make the prediction and then discarded. The prediction itself is stored, rather than the model. This approach can be useful when data is rapidly changing, and the model needs to be frequently updated to maintain accuracy.
Deployment
Once the model has been trained, it can be used to make predictions on new, unseen data. This involves feeding the test data into the model and evaluating its performance metrics, such as accuracy, precision, recall, and F1 score. The goal is to create a model that can accurately predict outcomes on new data.
You could theoretically have airflow answer requests using the trained model but it isn’t really meant for it. It is better to use airflow to keep the model up to date in an external system that can service requests more efficiently. If deployment in your system means using the model on blocks of data at once (doing analytics) the process can be scheduled similarly to data preprocessing. If individual requests come in and require service, best to build an API that will use the model to service those requests.
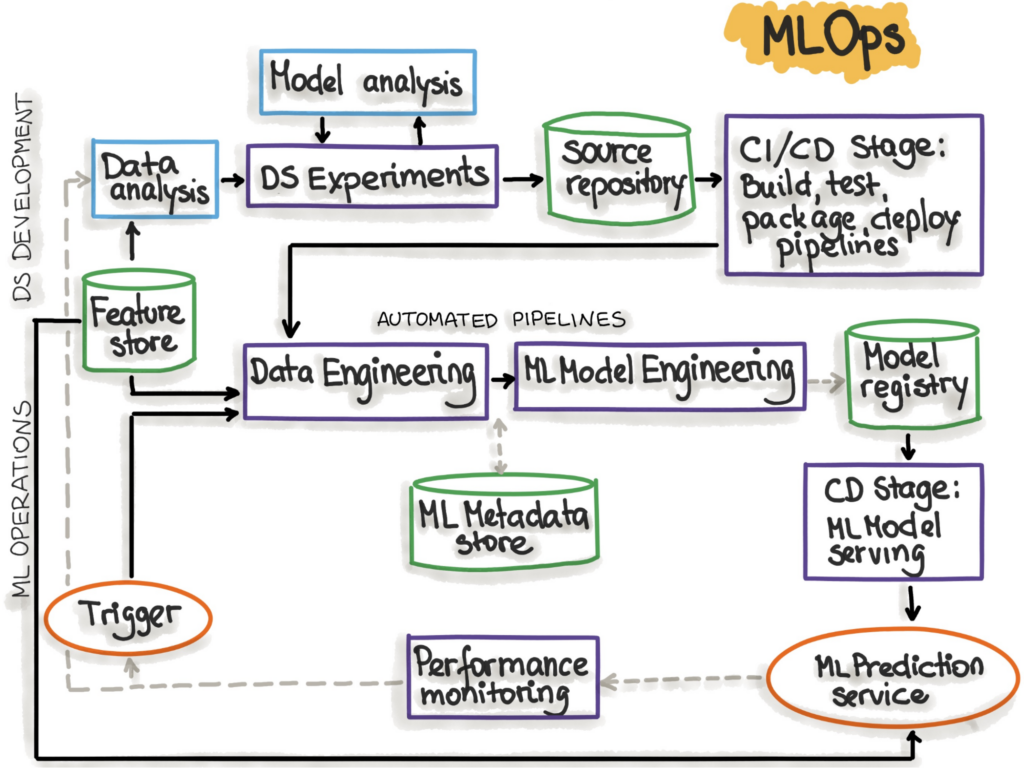
MLOps
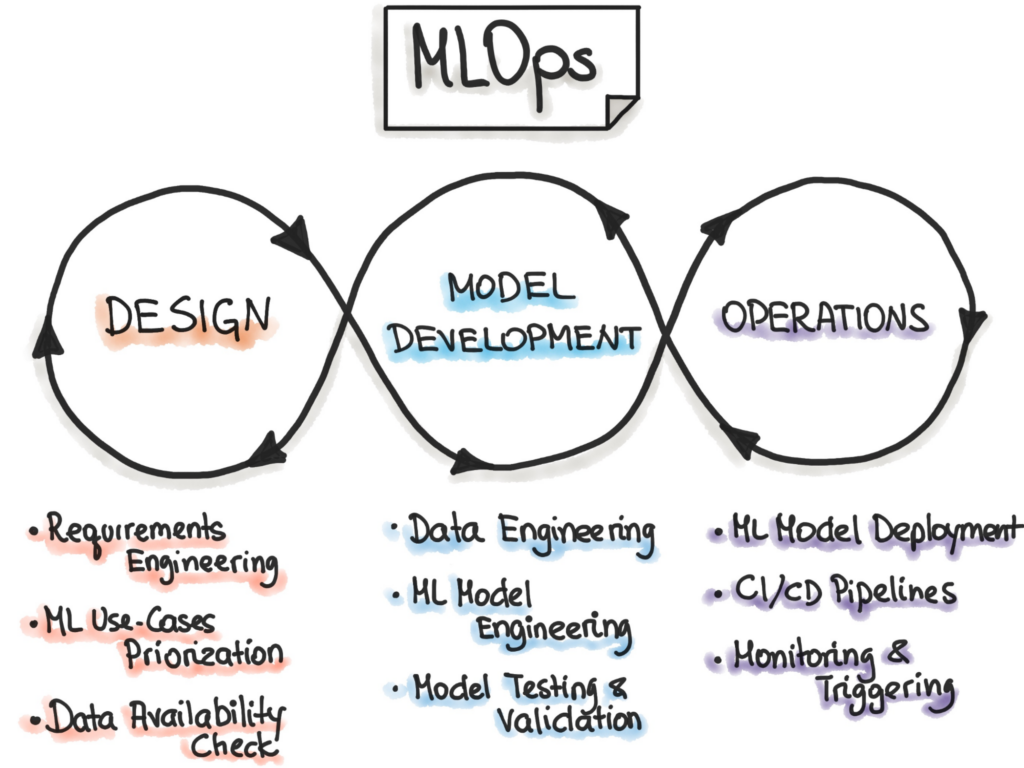
ML Ops encompasses all the topics we’ve discussed and more. The ML Ops process typically involves three main phases: design, development, and operations. In the design phase, the focus is on understanding the business use case, available data, and the structure of the software. In the development phase, data engineering for preprocessing steps and model selection and tuning are critical. Finally, in the operations phase, the emphasis is on delivering developed ML models through testing, monitoring, and versioning. By following the best practices of ML Ops, teams can streamline their ML workflows and build scalable, efficient, and accurate models that deliver real-world business value. Properly implemented ML Ops can help organizations stay ahead of the curve and achieve their goals in the fast-paced world of machine learning.
Cassandra.Link
Cassandra.Link is a knowledge base that we created for all things Apache Cassandra. Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra but to bring the Cassandra community together. Feel free to reach out if you wish to collaborate with us on this project in any capacity.
We are a technology company that specializes in building business platforms. If you have any questions about the tools discussed in this post or about any of our services, feel free to send us an email!

