In Data Engineer’s Lunch #80: Apache Spark Resource Managers, we discussed the different resource managers available for Apache Spark. We covered the local, standalone, YARN, and Kubernetes resource managers and discussed how each one allows the user different levels of control over how resources given to spark are distributed to Spark applications. The live recording of the Data Engineer’s Lunch, which includes a more in-depth discussion, is also embedded below in case you were not able to attend live. If you would like to attend a Data Engineer’s Lunch live, it is hosted every Monday at noon EST. Register here now!
Spark Resource Managers
Resource managers (a.k.a cluster managers) determine the distribution of resource and work on a given Spark cluster. Separate from the resources give to master/worker nodes, these systems determine how resources are split up within the nodes and how applications are granted access to them. This is also a different setting than –deploy-mode which deals mostly with the location of the driver (client mode puts it on the machine running the spark-submit while cluster mode puts it on the cluster).
Resource Manager Options
- Local (the validity of this as one of the resource managers is up for debate)
- Spark Standalone
- YARN
- Mesos (depreciated as of Spark 3.2.0 – up for removal)
- Kubernetes
Resource Manager – Local
Technically, local is not a resource manager, local mode forgoes the need for a resource manager by running everything within a single JVM process. Activated by providing local, local[n], or local[*] as the value for the –master flag when running spark binaries (spark-shell, spark-submit, pyspark). Local defaults to a single thread, local[n] creates n threads, and local[*] creates as many threads as cpu cores available to the JVM. If you don’t provide a –master flag value spark defaults to local[*].
Resource Manager – Spark Standalone
This resource manager comes bundled with open source spark. It requires a compiled version of Spark on each node to be able to run. Architecturally, this resource manager is simple, not providing extra functionality beyond the basic Spark capabilities.
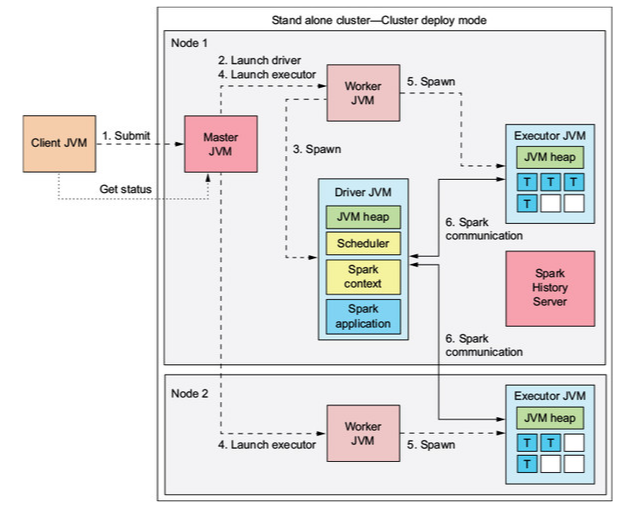
The cluster consists of a master process and potentially many worker processes. The master accepts applications and schedules worker resources. Worker processes launch executors that perform task execution. Users can launch a cluster using the start-master.sh and start-worker.sh scripts on relevant machines or set up the conf/workers file and use the provided launch scripts.
Spark Standalone Resources
The user configures the pool of resources available to the worker processes. Only allows FIFO scheduling between applications (if two request the same resources whoever asked first gets them). By default applications reserve all the cores available on the cluster. This would limit the number of jobs that can be run at once to one. To avoid this, set spark.cores.max in the SparkConf. The number of cores assigned to each executor is also configurable. If spark.executor.cores is set, several executors for an application can run on one worker. Otherwise limited to one executor per worker, that uses all the cores on that worker. Having a single master node means a single point of failure, this can be mitigated via ZooKeeper or local file system based per-node recovery.
Resource Manager – YARN
Yarn stands for Yet Another Resource Negotiator. Using Spark and YARN involves running Spark jobs on a cluster with YARN architecture. Consists of a single Resource Manager and a Node Manager for each node. Applications run inside containers, with an application master in a container by itself. In YARN the application master requests resources for applications from the Resource Manager. In Spark the Spark driver acts as the application master
Node managers track resource usage and report back to the resource manager.
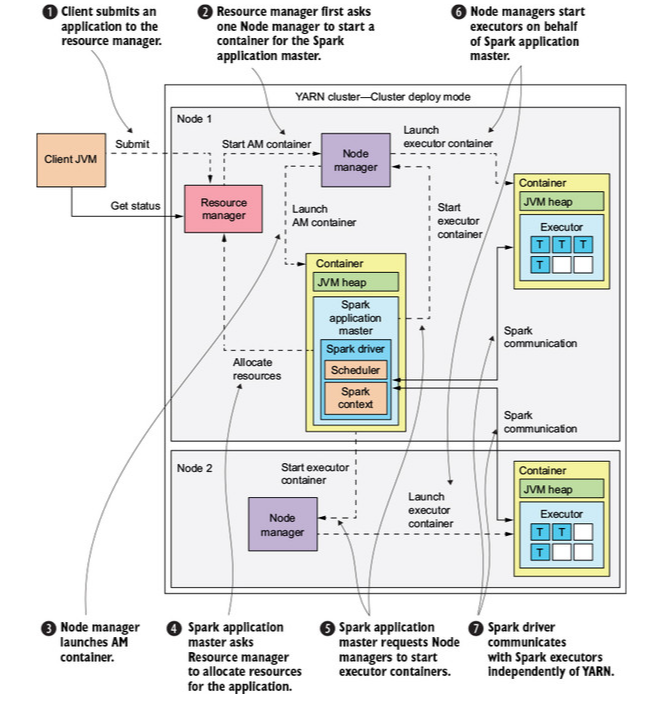
YARN Resources
YARN/Spark has three modes of resource scheduling. FIFO is the same as the FIFO scheduler in Spark standalone. Capacity guarantees resource availability for organizations. With fair scheduling all applications get an equal share of cluster resources. YARN defaults to two executors per node and one core per executor. Needs memory overhead for internal JVM container processes – if executor uses memory over executor memory + memoryOverhead, container crashes. The YARN UI for applications is different from Spark Standalone’s Spark Master UI. YARN offers dynamic allocation – basically an application starts with a specified number of executors and can request more from the resource manager if tasks are waiting for a long time.
Resource Manager – Mesos
Mesos uses masters, workers, and frameworks (similar to applications in Spark Standalone). Masters schedule worker resources among frameworks that want them and worker launch executors which execute tasks. Mesos can schedule non-Spark applications and resources like disk space and network ports as well as CPU and memory. Mesos offers resources to frameworks rather than the framework demanding resources from the cluster.
Remember Mesos is depreciated in Spark 2.3.0+ and is slated for removal.
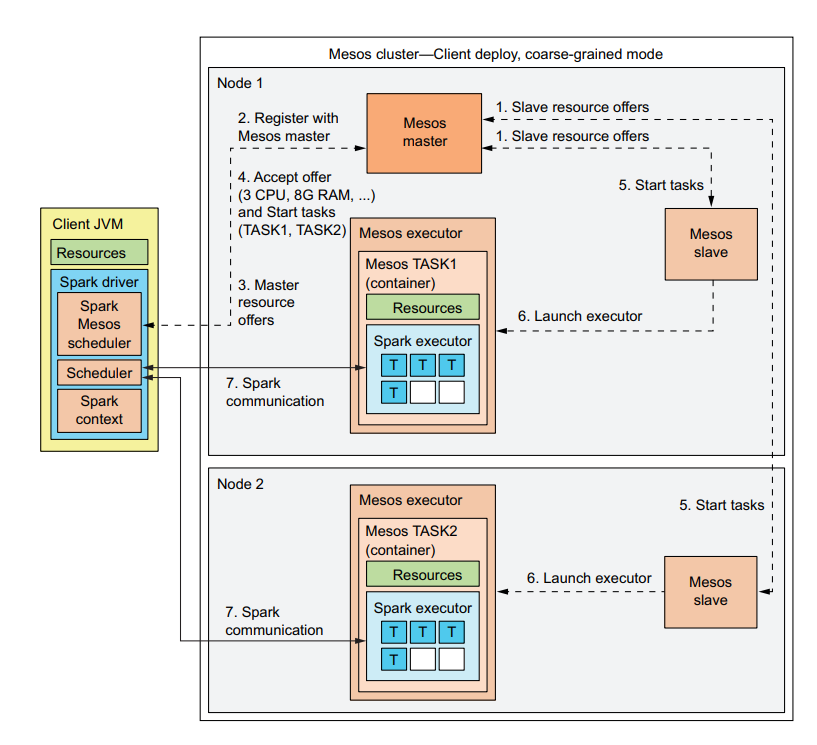
Mesos Resources
In coarse-grained mode, runs one Spark executor per Mesos worker. In fine-grained mode, runs one Spark executor per Spark task (one type of Mesos task). Coarse grained and fine grained are equivalent to scheduler modes. Mesos tasks executed in containers – either linux cgroups or docker containers. Mesos has its own UI showing frameworks the same way applications are shown in the Spark UI. Scheduling done by the resource-allocation module on the Mesos master and the framework’s internal scheduler (the fine-grained and coarse-grained Spark scheduler live here). Uses the Dominant Resource Fairness algorithm, distributing other resources by offering them to frameworks currently using the least resources by the DRF. If they need more resources they can accept but if they don’t or are offered too big a share, they can reject the offer.
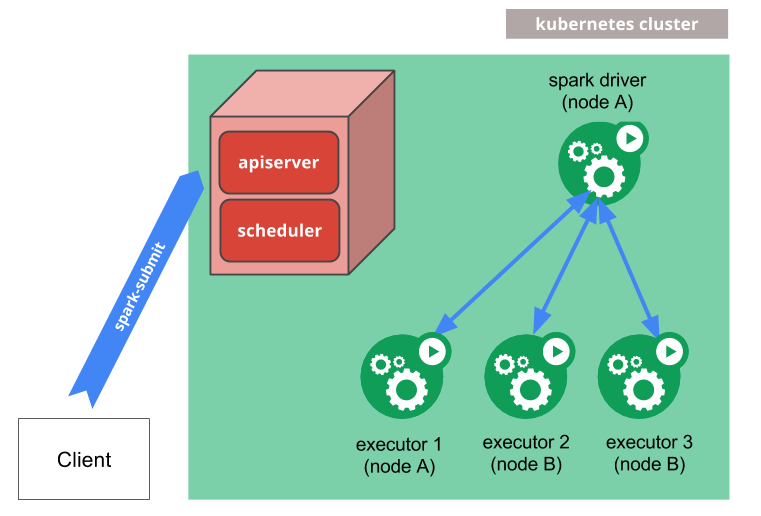
Resource Manager – Kubernetes
Spark applications can be run on a Kubernetes cluster. Clients use spark-submit to submit Spark applications to a Kubernetes cluster. Kubernetes creates a Spark driver in a Kubernetes pod. The driver creates executors in their own pods.
Once the application is complete the executor pods terminate and get cleaned up and the driver pod hangs around in the Kubernetes APi with its logs until it gets cleaned up. Spark 2.3+ ships with a dockerfile for building a Docker image for use with Kubernetes as well as tools for. Resources for the application are all managed by Kubernetes internals.
Conclusion
Spark resource managers facilitate the running of Spark applications on hardware. They ultimately exist to allow the communication between drivers and executors that make Spark processes happen. There are a number of ways to make this happen, but using existing cluster resource managers and mapping their concepts onto spark can enable the creation of clusters in ways that are faster and easier or require less maintenance. In return these resource managers also affect you default resource allocation for handing out Spark cluster resources to individual applications.
Resources
Book
Spark in Action – Jean-Georges Perrin
Articles
Cassandra.Link
Cassandra.Link is a knowledge base that we created for all things Apache Cassandra. Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra but to bring the Cassandra community together. Feel free to reach out if you wish to collaborate with us on this project in any capacity.
We are a technology company that specializes in building business platforms. If you have any questions about the tools discussed in this post or about any of our services, feel free to send us an email!