
In Data Engineer’s Lunch #27 Data Processing with Containers: Kubernetes Tools for Data Engineering, we will discuss data processing with different container tools including Docker, Kubernetes, Airflow, Argo, and Kubeflow. The live recording of the Data Engineer’s Lunch, which includes a more in-depth discussion, is also embedded below in case you were not able to attend live. If you would like to attend a Data Engineer’s Lunch live, it is hosted every Monday at noon EST. Register here now!
Why Data Processing with Containers?

There are a lot of benefits of using containers and Rahul explains in detail why we should use them. Language, Framework, Hardware, Cloud, and Data agnostic are the main benefits of using Data Processing with Containers.
Why now?
Kubernetes is basically everywhere, docker makes it easy to write containerized processes. And with support from giant companies like Amazon and Google providing cloud-based solutions, it’s easy to see why Kubernetes has become a standard.
DIY: ETL Docker Data Pipeline
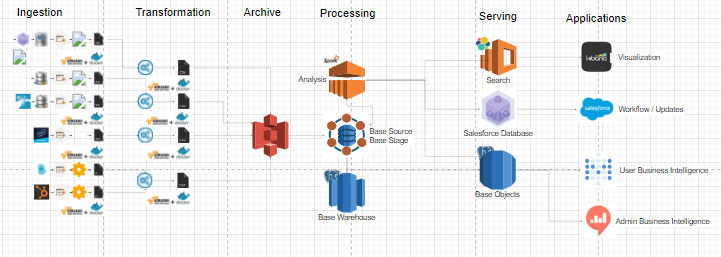
Rahul starts off by explaining how all of the Ingestion and Transformation got standardized into containers and each process like for example data would be gathered from Heroku/JSON/MySQL and the different ways of exporting it as csv utilizing S3.
Data Processing with Containers
Pachyderm

The file system from pachyderm is like a git for datasets where when you do a change it does a copy of the previous version, aside from that it has a pipeline system for containers on top of that data. In general great tool which utilizes Kubernetes and containers.
Airflow
Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.

Argo
Argo Workflows is an open-source container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo Workflows is implemented as a Kubernetes CRD.

Kubeflow
The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. The goal is not to recreate other services, but to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures. Anywhere you are running Kubernetes, you should be able to run Kubeflow.

Cassandra.Link
Cassandra.Link is a knowledge base that we created for all things Apache Cassandra. Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra but to bring the Cassandra community together. Feel free to reach out if you wish to collaborate with us on this project in any capacity.
We are a technology company that specializes in building business platforms. If you have any questions about the tools discussed in this post or about any of our services, feel free to send us an email!

