
In Data Engineer’s Lunch #47, we will use Kubernetes to deploy Airflow. The live recording of the Data Engineer’s Lunch, which includes a more in-depth discussion, is also embedded below in case you were not able to attend live. If you would like to attend a Data Engineer’s Lunch live, it is hosted every Monday at noon EST. Register here now!
Why Airflow on Kubernetes?
Since its inception, Airflow’s greatest strength has been its flexibility. Airflow offers a wide range of integrations for services ranging from Spark and HBase, to services on various cloud providers. Airflow also offers easy extensibility through its plug-in framework. However, one limitation of the project is that Airflow users are confined to the frameworks and clients that exist on the Airflow worker at the moment of execution. A single organization can have varied Airflow workflows ranging from data science pipelines to application deployments. This difference in use-case creates issues in dependency management as both teams might use vastly different libraries for their workflows.
To address this issue, we’ve utilized Kubernetes to allow users to launch arbitrary Kubernetes pods and configurations. Airflow users can now have full power over their run-time environments, resources, and secrets, basically turning Airflow into an “any job you want” workflow orchestrator.
The Kubernetes Operator
Before we move any further, we should clarify that an Operator in Airflow is a task definition. When a user creates a DAG, they would use an operator like the “SparkSubmitOperator” or the “PythonOperator” to submit/monitor a Spark job or a Python function respectively. Airflow comes with built-in operators for frameworks like Apache Spark, BigQuery, Hive, and EMR. It also offers a Plugins entrypoint that allows DevOps engineers to develop their own connectors.
Airflow users are always looking for ways to make deployments and ETL pipelines simpler to manage. Any opportunity to decouple pipeline steps, while increasing monitoring, can reduce future outages and fire-fights. The following is a list of benefits provided by the Airflow Kubernetes Operator:
- Increased flexibility for deployments:
Airflow’s plugin API has always offered a significant boon to engineers wishing to test new functionalities within their DAGs. On the downside, whenever a developer wanted to create a new operator, they had to develop an entirely new plugin. Now, any task that can be run within a Docker container is accessible through the exact same operator, with no extra Airflow code to maintain. - Flexibility of configurations and dependencies: For operators that are run within static Airflow workers, dependency management can become quite difficult. If a developer wants to run one task that requires SciPy and another that requires NumPy, the developer would have to either maintain both dependencies within all Airflow workers or offload the task to an external machine (which can cause bugs if that external machine changes in an untracked manner). Custom Docker images allow users to ensure that the tasks environment, configuration, and dependencies are completely idempotent.
- Usage of kubernetes secrets for added security: Handling sensitive data is a core responsibility of any DevOps engineer. At every opportunity, Airflow users want to isolate any API keys, database passwords, and login credentials on a strict need-to-know basis. With the Kubernetes operator, users can utilize the Kubernetes Vault technology to store all sensitive data. This means that the Airflow workers will never have access to this information, and can simply request that pods be built with only the secrets they need.
Architecture
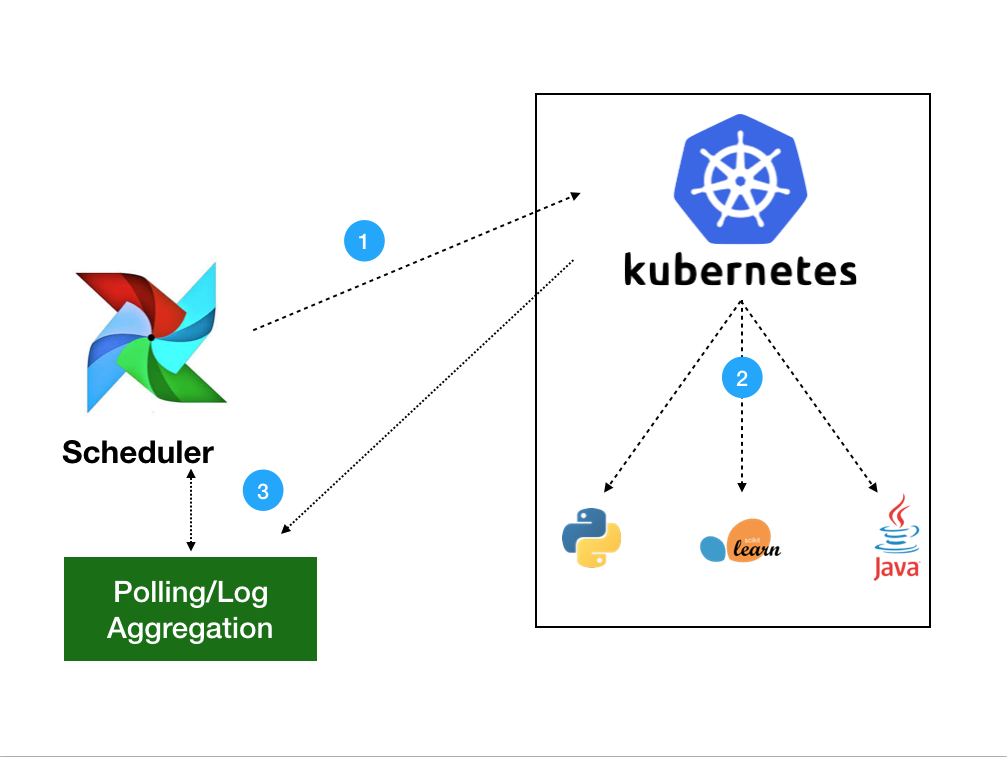
If you missed Data Engineer’s Lunch #47: Airflow on Kubernetes, it is embedded below! Additionally, all of our live events can be rewatched on our YouTube channel, so be sure to subscribe and turn on your notifications!
Cassandra.Link
Cassandra.Link is a knowledge base that we created for all things Apache Cassandra. Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra but to bring the Cassandra community together. Feel free to reach out if you wish to collaborate with us on this project in any capacity.
We are a technology company that specializes in building business platforms. If you have any questions about the tools discussed in this post or about any of our services, feel free to send us an email!

