
Apache Cassandra is a free and open-source NoSQL database management system that is designed to handle large amounts of data with no single point of failure. In this post, I’m going to highlight 3 different but useful tools that make life easier when using Apache Cassandra.
Zipkin
The first tool that I’m going to talk about is called Zipkin. It is a distributed tracing system that helps gather timing data needed to troubleshoot latency problems in service architectures. Primary features include the collection and lookup of said data. Zipkin uses trace IDs to find and summarize data otherwise you can also query data based on various attributes.
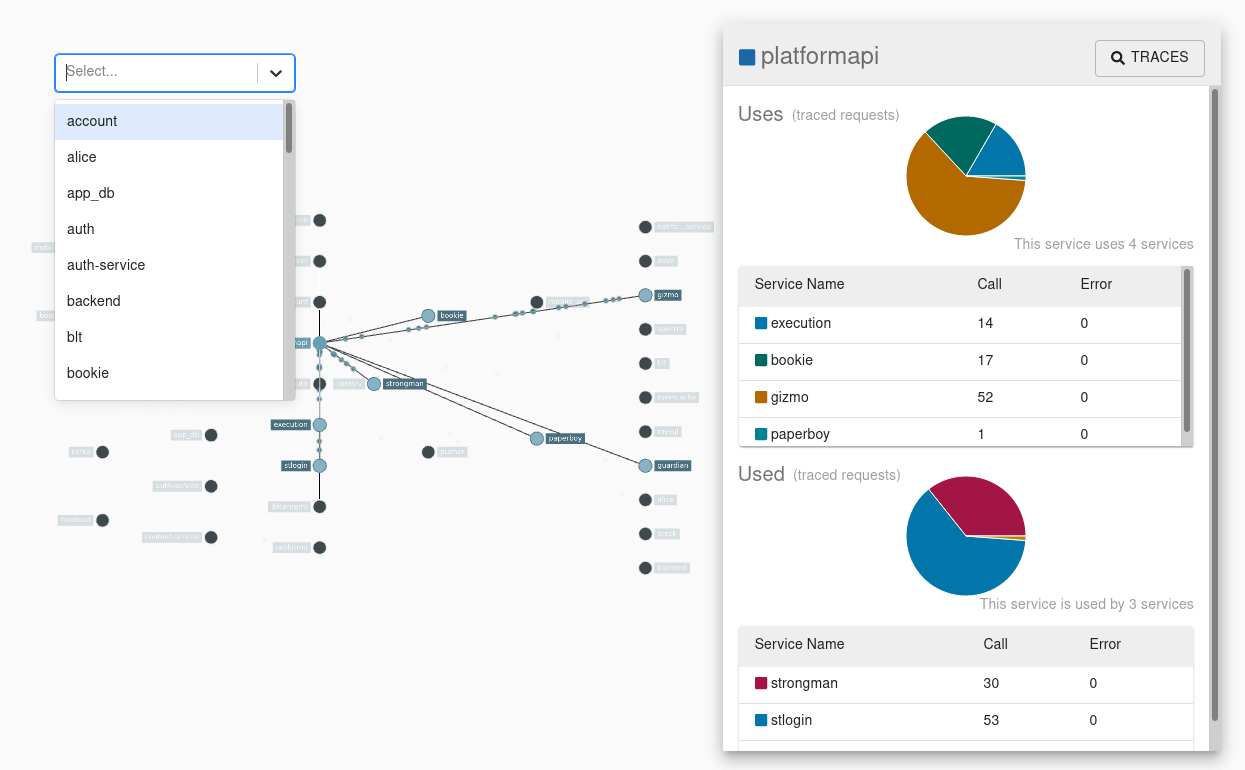
The image above shows the dependencies between the traced requests through each app. Zipkin uses tools such as Kafka to report data. That data is then stored in memory, or persistently with a supported back-end such as Apache Cassandra or Elasticsearch.
Newts
The second tool we are going to talk about is called Newts. It is a massively scalable time-series data store based on Apache Cassandra. Time-series data is data that collectively represents how a system/process/behavior changes over time. This type of data-set only tracks changes to the overall system as INSERTs, not UPDATEs. The main features of this tool include:
- High throughput – Newts is built upon Apache Cassandra, a write-optimized, fully distributed partitioned row store.
- Grouped access – It’s common to collect, store, and retrieve metrics together, (think bytes in and bytes out, or 1, 5, and 15-minute load averages.); Newts allows for similar metrics to be grouped together, for more efficient storage and retrieval.
- Late aggregation – Most time-series solutions perform in-line aggregations for purposes of later plotting visualizations, even though the ratio of reads to writes is staggeringly small. Newts performs plot aggregations at the time of the read.
- Searchable Metadata – Fully searchable sample resource metadata.
RESTBase
Finally, the last tool I’m going to talk about is called RESTBase. This is a tool that provides a high-level table storage service abstraction similar to Amazon DynamoDB or Google DataStore on top of Apache Cassandra. It’s main features include:
- Basic table storage service with REST interface, backed by Cassandra, implementing the RESTBase table storage interface
- Multi-tenant design: domain creation, prepared for per-domain ACLs
- Table creation with declarative JSON schemas
- Limited automatic schema migrations
- Paging
Cassandra.Link is a knowledge base that our team created to act as a central POI for all things Apache Cassandra. Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra but we want to bring the Cassandra community, no matter what variant they use, together. Feel free to reach out if you wish to collaborate with us on this project in any capacity.
We are a technology company that specializes in building business platforms. If you have any questions about the tools discussed in this post or about any of our services, feel free to send us an email!

