
This post will cover the installation of TableAnalyzer and the use of the tool for data model review. TableAnalyzer is useful for troubleshooting problems with Cassandra tables. We can then tie those problems to particular issues with the data model and use it to drive changes. Check out Using TableAnalyzer – Anant’s Tool for Analysis of Cassandra Tables as well!
Install dependencies
Install Python dependencies using pip. Make sure to use pip3 / python3:
pip3 install -r requirements.txtPrepare for SSH: Add SSH Keys (if using SSH)
NOTE: This is only applicable if you are using SSH to run nodetool commands on Cassandra nodes.
You will need to add copy your pem files to where TableAnalyzer can find them. In the TableAnalyzer directory, in a folder keys, add pem files needed to ssh into each node to be analyzed.
mkdir -p cassandra-analyzer/offline-log-collector/TableAnalyzer/keys/
cp <path-to-pem-file>/my-private-key.pem cassandra-analyzer/offline-log-collector/TableAnalyzer/keys/
These will need to be referenced in your environments.yaml file in the next step.
Set configuration: Create environments.yaml file
From the TableAnalyzer directory, in folder ./config, create the file environments.yaml. If it does not yet exist, use a copy of environments-sample.yaml:
cd cassandra-analyzer/offline-log-collector/TableAnalyzer/config/
cp ./environments-sample.yaml ./environments.yaml
vim environments.yaml
# …Now fill out each region, each cluster for each region, each datacenter for each cluster, and each node’s ip address for each datacenter.
Setting the different values in the environments.yaml config
TableAnalyzer needs to the topology of your clusters. Specifically, we refer to the region, cluster, datacenter, and nodes in both the environments.yaml config file and in the CLI argos when you run the script.
Note that TableAnalyzer only runs on a single datacenter at a time, and consequently the spreadsheet that TableAnalyzer generates is only for a single datacenter. If you want to analyze several datacenters, you will have to run TableAnalyzer multiple times. However, if you put the information for all of your datacenters in the single environments.yaml file, you can use a single environments.yaml config file and TableAnalyzer will know what datacenter to run against by way of CLI args.
Below is a description of how we use the values set for region, cluster, and datacenter in our script.
“Region”
- Should probably be one of: us-east-1|usw|us|uswest (or something like that)
- The same kind of idea as “environment”, we use only for our script to namespace these nodes
In our examples below, we use uswest for our region.
“Environment”
- Should probably be one of: dev/stage/prod
- is just a way to namespace these nodes for use by script.
- Does not have an impact on where the script looks to collect the files from, but hasn’t impact on the path we collect the files to. (will go to: data/<region>/<environment>/<ip>.txt
In our examples below, we use prod for our environment.
“Datacenter”
Often we use one of “cassandra” or “spark” in our examples, but really this can be any arbitrary string, just needs to be whatever we defined in the environments.yaml file, and line up with the directory we created in the data file. For example, can also be “dc1” etc.
In our examples below, we use cassandra for our datacenter.
Example Configuration
# region:
# cluster:
# datacenter:
us:
prod:
cassandra:
- 192.168.0.1
- 192.168.0.2
- 192.168.0.3
spark:
- 192.168.0.4
key: keyfile.pem
prod2:
cassandra:
- 192.168.0.11
- 192.168.0.12
- 192.168.0.13
spark:
- 192.168.0.14
key: keyfile.pem
stage:
cassandra:
- 192.168.1.1
- 192.168.1.2
- 192.168.1.3
spark:
- 192.168.1.4
key: keyfile.pem
Create Data Directories
Currently, our scripts do not make data directories for you, and so you have to make directories for each database first in the TableAnalyzer directory, within the data folder.
# mkdir -p ./data/<region>/<environment>
mkdir -p ./data/uswest/prodAnalyze Tablestats using Spreadsheet
Now that we have a spreadsheet to help us visualize our table stats, we can now analyze the data and search for problems in our data model. There are three main problems that we generally look for, which we like to call “The Three Stooges” of Cassandra:
- Wide Partitions
- Skew
- Tombstones
How to use the spreadsheet
The spreadsheet by default shows information for each node (column: “Hostname”) by table (column: “Table”). This means that we can easily find different kinds of skew by sorting rows by one of the other columns, and then comparing values in that column to other nodes that hold data for a particular table.
For example, to find “Traffic Skew” for reads, we can sort by “Table” first, then by “ReadCount”.

Now, all nodes that hold data for a given table are grouped together, and the read counts for each node can be easily compared to each other.
A similar process can be applied for other types of skew as well as Wide Partitions and Tombstones. We sort primarily by the tablename, and then secondarily by the column that is relevant for the particular type of datamodel issue that we want to identify.
Further Reading
For further information on identifying and solving these data model issues, see our blog at https://blog.anant.us/common-problems-cassandra-data-models/. This documentation borrows heavily from this blog post as well.
Data Model Review
Stooge #1: Wide Partitions

Description:
A partition is the fundamental unit of replication in Cassandra. A wide partition means that data is collecting in a large bucket rather than smaller ones. Partitions should not be bigger than 100MB.
Potential Side-effects:
Wide partitions can potentially cause latency since it takes longer to perform reads and writes when the partition is large. Wide partitions can also potentially create a large amount of tombstones. See below for information on identifying tombstones.
How to Identify Using Spreadsheet:
- Sort by column “CompactedPartitionMaxBytes” (avg, and min also good)
Stooge #2: Skew

Introduction
You can find information on different types of skew below, including what columns in the spreadsheet to sort by in order to find that particular type of skew.
Partition Skew
Description:
Partition skew is when a particular table has some partitions that are significantly larger size than others. Wide partitions (the first of the “Three Stooges”) is always a problem, but sometimes some nodes have wide partitions though others do not. If so, this kind of skew can be a cause and/or symptom of a different data model issue and require a different solution.
The size of a partition can be “larger” either when measuring by bytes (e.g., one node has partitions for a given table that are 500MB and another that has partitions that are 50MB) or when measuring by row count (e.g., one node has partitions for a given table that hold 500 rows and another node has partitions for that table that hold only 100 rows). Either way, this kind of skew will have an impact on Cassandra’s performance.
nodetool tablestats does not return row counts, but it does return the partition size in bytes. Also, since the partition key for this table will have a direct impact on the partitioning, partition key count should be looked at as well.
Look for:
- Keys/Partitions across Nodes for Table
How to Identify Using Spreadsheet:
Sort by partition-related values (columns: “CompactedPartitionMinimumBytes”, “CompactedPartitionMaximumBytes”, and “CompactedPartitionMeanBytes”) and partition-key count (column: “NumberOfKeys”).
Data Skew
Description:
Data skew is when the SSTables count or disk space size for a particular Cassandra table is unevenly distributed across nodes (e.g., one node has 100 sstables and another has only 10 sstables).
Look for:
- SSTables number across Nodes for Table
- Live Data across Nodes for Table
- All data / Snapshot Data across Nodes for Table
How to Identify Using Spreadsheet:
Sort by values related to disk space (columns: “SpaceUsedlive”, “SpaceUsedTotal”, and “SpaceUsedSnapshots”) and SSTable count (column: “SSTableCount”).
Traffic Skew
Description:
Traffic skew refers to Read and/or Write discrepancies across nodes for a given table. Also watch out for tables that do not have any reads or writes at all.
While this is not an indicator of “skew”, this does mean that this table is not being used at all and you should consider backing up the data somewhere and then dropping the table altogether so Cassandra does not have to continue managing the rows for this table.
How to Identify Using Spreadsheet:
Sort by values related to read and write count (columns: “ReadCount” and “WriteCount”).
Tombstone Skew
Description:
Tombstone skew is when there is an uneven distribution of tombstones across nodes for a given table. A large amount of tombstones (the third of the “Three Stooges”) is always a problem, but sometimes some nodes have a large amount of tombstones though others do not. If so, this kind of skew can be a cause and/or symptom of a different data model issue and require a different solution.
How to Identify Using Spreadsheet:
Sort by Tombstone related values (columns: “AverageTombstones”, “MaximumTombstones”) and look for large discrepancy between nodes.
Latency Skew
Description:
Latency skew is when there is an uneven distribution of read or write latency across nodes for a given table.
How to Identify Using Spreadsheet:
Sort by values related to Latency (columns: “ReadLatency”, “WriteLatency”).
Stooge #3: Tombstones
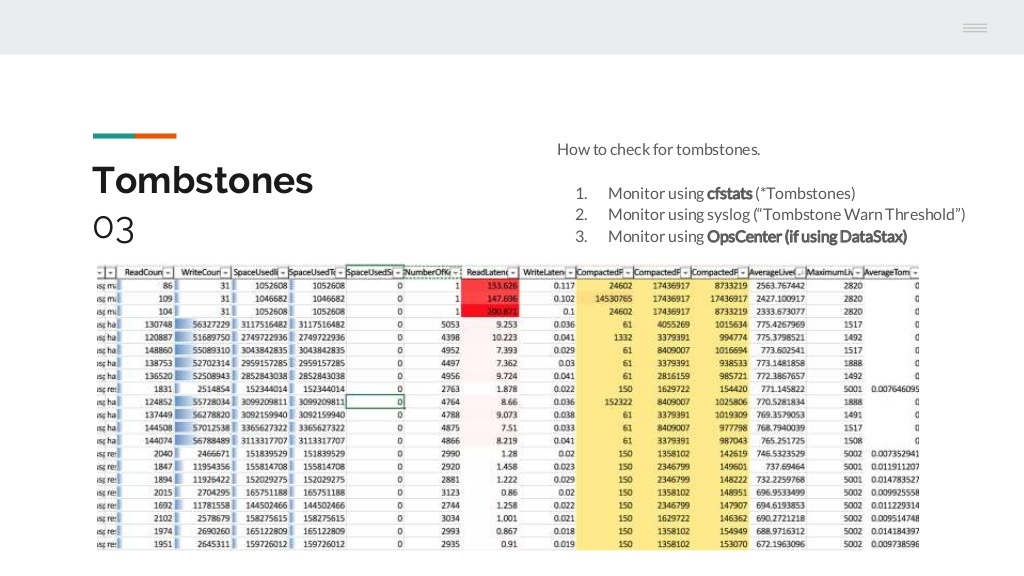
Description:
Tombstones are Cassandra’s way of being efficient with writes. It deletes data after the fact in compactions. When data is deleted, or a null value is inserted/ updated in an existing table, a tombstone record is added.
When under normal levels, they are not a problem. They become problematic when tremendous amounts of tombstones accumulate together because of frequent updates that add nulls, wide partitions with many rows in one partition, or due to data skew. What Cassandra does on a read is to reconcile the immutable writes into the current state of the data. This takes memory and computation and is magnified even more if the partition is large.
How to Identify Using Spreadsheet:
Sort by Tombstone related values (columns: “AverageTombstones”, “MaximumTombstones”) and look for high tombstone values.
Potential side-effects
- Latency
- Skew
Potential Causes
- Skew
- Wide Partition
Cassandra.Link
Cassandra.Link is a knowledge base that we created for all things Apache Cassandra. Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra but to bring the Cassandra community together. Feel free to reach out if you wish to collaborate with us on this project in any capacity.
We are a technology company that specializes in building business platforms. If you have any questions about the tools discussed in this post or about any of our services, feel free to send us an email!

