Introduction
Welcome to the next blog in our series, where we dive into real-world examples of Kafka and Airflow implementation. In this blog, we will explore how Airbnb, the leading online marketplace for vacation rentals, utilizes Kafka and Airflow in its data pipeline. By leveraging Kafka’s real-time data ingestion and Airflow’s workflow management capabilities, Airbnb ensures efficient and scalable data processing, enabling them to provide a seamless experience for their users.
Overview of Airbnb’s Data Pipeline
Airbnb’s data pipeline is a critical component of its business operations. It encompasses real-time data ingestion, event-driven workflows, and batch processing to handle the massive amounts of data generated by their platform. Real-time data ingestion allows Airbnb to capture user interactions, bookings, and reviews as they happen, enabling them to provide timely and personalized recommendations to their users. Event-driven workflows ensure that the right actions are triggered based on specific events, such as sending notifications or updating search indexes. Batch processing handles large-scale data transformations, aggregations, and analytics to generate insights and support decision-making.
Kafka Implementation at Airbnb At Airbnb, Kafka serves as the foundation for real-time data ingestion and streaming. By leveraging Kafka’s distributed and scalable architecture, Airbnb can handle high data volumes while ensuring data integrity and reliability. Airbnb utilizes Kafka Connect, a tool for integrating external systems with Kafka, to ingest data from various sources into Kafka topics. They also leverage Kafka Streams, a client library for building real-time processing applications, to perform stream processing tasks such as filtering, aggregating, and enriching data in real-time. This enables Airbnb to process and analyze data as it flows through its pipeline, facilitating quick and informed decision-making.
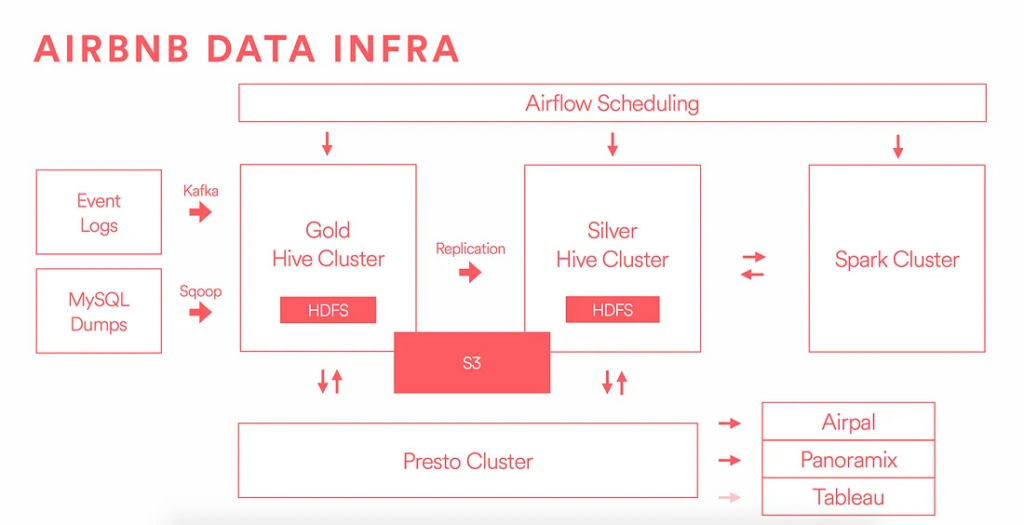
Source: https://medium.com/airbnb-engineering/data-infrastructure-at-airbnb-8adfb34f169c
Airflow Implementation at Airbnb Airflow plays a crucial role in managing the complex workflows and orchestration tasks at Airbnb. With Airflow, Airbnb can schedule and execute data processing tasks in a highly configurable and scalable manner. They define workflows as directed acyclic graphs (DAGs), representing the dependencies and execution order of tasks. Airflow’s user-friendly interface allows Airbnb’s data engineers to monitor, troubleshoot, and manage workflows effectively. They utilize Airflow operators, which represent repetitive individual tasks within a workflow, to perform various data processing activities such as data transformations, aggregations, and machine learning model training.
HOW IT WORKS:
- User Interaction:
- Users visit the Airbnb website and browse available listings.
- They select a specific listing and proceed to book the house online.
- Event Generation:
- When a user initiates the booking process, an event is generated in the Airbnb system.
- This event is produced as a message in Kafka, indicating the user’s intent to book a particular house.
- Kafka Stream Processing:
- Kafka streams consume the booking event message from the Kafka topic in real-time.
- The stream processing application running on Kafka processes and validates the event data.
- Additional data enrichment and validation steps may be performed, such as checking availability, verifying user credentials, and performing fraud detection.
- Workflow Orchestration with Airflow:
- Airflow is responsible for managing the workflow of processing the booking event.
- Airflow schedules and triggers the necessary tasks and data processing steps based on predefined workflows and dependencies.
- Tasks may include data validation, updating inventory, generating booking confirmation emails, and initiating payment processing.
- Data Processing and Updates:
- The workflow tasks orchestrated by Airflow process the booking event and update relevant data in the Airbnb system.
- For example, the booking details are stored in the database, availability is updated, and payment information is processed.
- User Feedback and Rating:
- After the user completes their stay, they have the option to provide feedback and rate their experience.
- When a user submits a review or rating, an event is generated and produced to Kafka.
- The Kafka stream processing and workflow orchestration steps are repeated to handle the review and rating event, updating the relevant data in the Airbnb system.
Benefits and Impact at Airbnb
The implementation of Kafka and Airflow brings significant benefits to Airbnb’s data pipeline. By leveraging Kafka’s real-time data ingestion capabilities, Airbnb can capture and process data as it happens, enabling them to provide timely and personalized recommendations to their users. Kafka’s fault-tolerant and scalable architecture ensures that data is reliably and efficiently processed, even during peak loads. Airflow’s workflow management capabilities enable Airbnb to orchestrate complex data processing tasks, ensuring efficient and reliable operations.
The visibility and monitoring features of Airflow allow Airbnb’s data engineering teams to track the progress and performance of their workflows, enabling quick identification and resolution of issues.
Conclusion
In this blog, we explored how Airbnb leverages Kafka and Airflow in their data pipeline. We discussed the importance of real-time data ingestion, event-driven workflows, and batch processing in Airbnb’s operations. The combination of Kafka and Airflow empowers Airbnb to handle massive data volumes, ensure data integrity, and execute complex workflows with ease. Anant’s extensive experience working with Real-Time Data Enterprise Platforms, including Apache Kafka and Airflow, allows us to incorporate them into our own custom pipelines curated to meet the specific needs of your enterprise. If you’re interested in implementing Kafka and Airflow in your own data pipeline or need assistance with data engineering challenges, contact Anant. Our team of experienced professionals can provide expert guidance, customization, troubleshooting, and support to help you optimize your data platform and achieve your data-driven goals. Stay tuned for the next blog, where we’ll dive into real-world examples of Kafka and Airflow implementation at Lyft, showcasing how these technologies power their data pipelines and drive their business success.
The Role and Impact of Anant Services and Expertise
Anant’s extensive experience working with Real-Time Data Enterprise Platforms, including Apache Kafka and Airflow, makes them a valuable partner in Real-Time Data pipelines. Here’s how Anant’s services and expertise enhance your pipelines:
Data Lifecycle Management Toolkit: Anant’s DLM Toolkit incorporates our Playbook principles and offers a comprehensive set of features, tools, and methodologies to facilitate the data pipeline process. The toolkit includes components such as the data manager, migrator, and catalog, which simplify the data pipeline steps and accelerate data platform success.
Expert Guidance: Anant’s team of experienced professionals provides expert guidance throughout the data pipeline process. We understand the intricacies of Kafka and Airflow and can provide valuable insights, best practices, and recommendations to ensure a secure pipeline.
Customization and Optimization: Anant’s services are tailored to meet the unique requirements of each data pipeline project. We work closely with businesses to understand their specific needs, optimize the transformation strategy, and implement customized solutions that align with their data platform goals.
Troubleshooting and Support: Data pipeline processes can encounter unexpected challenges and issues. Anant’s services include robust error handling, logging, and troubleshooting mechanisms to address any roadblocks. Our support ensures that any hurdles are resolved promptly, minimizing downtime and ensuring data integrity.
Continuous Improvement: Anant’s DLM approach promotes continuous improvement even beyond the data pipeline process. By documenting and monitoring various dimensions, including contexts, responsibilities, approach, framework, and tools, we enable businesses to enhance their data platforms, optimize performance, and stay aligned with evolving industry trends.