
In Data Engineer’s Lunch #67: Machine Learning – Feature Selection, we discussed the process of picking particular, relevant data features out of a wider data set, to be used to perform model training. The live recording of the Data Engineer’s Lunch, which includes a more in-depth discussion, is also embedded below in case you were not able to attend live. If you would like to attend a Data Engineer’s Lunch live, it is hosted every Monday at noon EST. Register here now!
Overview
Feature selection describes the process of picking particular, relevant data features out of a wider data set, to be used to perform model training. It is a part of the larger data preparation step that takes place at the start of any machine learning process.
Data Preparation
Data preparation deals with transformations applied to data that prepare it for use with machine learning algorithms. Previously, we’ve covered a number of methods within the field here. Vectorization and Encoding help organize raw data into a form that ML models can work with
Standardization can help to better express the variance within data and prepare it for models that expect data within certain ranges.
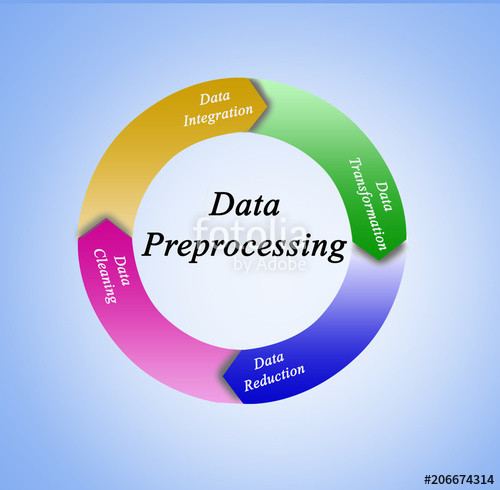
Imputation is one of a number of methods for dealing with missing fields for particular rows within your data. Feature selection actually falls within the same category as PCA, a previously covered topic. Both methods are types of dimensionality reduction. Dimensionality reduction focuses on removing irrelevant data from the data set to reduce computational costs, improve model performance, and work towards “legibility” – or the ability of the model to be understood by humans.
Feature Selection
Feature selection, as a subcategory of dimensionality reduction, is concerned with picking the most relevant features out of a dataset. It is a process for removing irrelevant or misleading columns from a dataset before any models are trained. Just like ML models in general, feature selection methods can be supervised or unsupervised, depending on whether the data that they interact with is labeled or not.
Unsupervised feature selection processes do not have a label against which they can compare the relevance of the data, so the most it can accomplish is to remove redundant data from the data set.
Supervised processes can compare how highly certain fields are correlated with the label we want the model to predict in the end, so data can be defined as irrelevant if it has no bearing on that outcome.
Essentially, supervised methods are about the relationship between your data and the labels while unsupervised methods are about the relationships between your data and the rest of your data.
Unsupervised methods can work within singular features to remove ones that even in isolation fail to add information to the wider data set. Variance Thresholds are used to remove any fields with variance below a certain value. In the most extreme case, fields that contain the same value for every row in the dataset can safely be dropped. Variance thresholds allow less extreme settings but generally accomplish the same type of thing.
They can also work across the entire set of features to remove redundant ones. A correlation matrix can be built between fields in the data set. Fields that show extremely high correlation with each other can be chosen between. For an extreme example consider a data set that contains two fields measuring the exact same thing with different units. At most, one of those should make it into the training set. In this test they would show 100% correlations with each other signaling that we only need one.
Supervised Methods
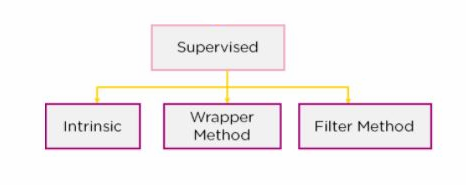
Supervised filter selection methods compare predictor fields to the label field, picking out the most relevant fields to prediction outcomes.
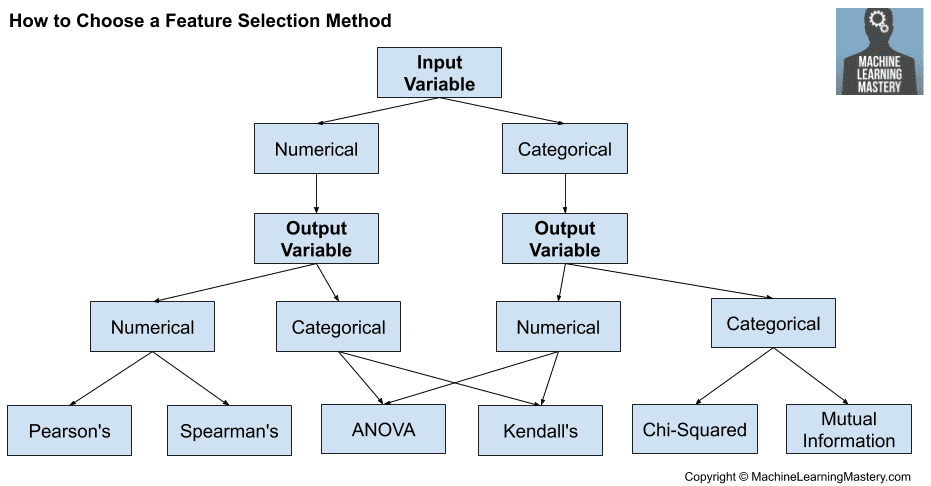
Filter methods use statistical analysis to perform feature selections. Which algorithms need to be used depend on the type of the fields of the label fields and the predictor field being analyzed.Each of these combinations have various associated statistical tests. Some of these are familiar like Pearson’s Correlation Coefficients, a measure of correlation and ANOVA, a measure of statistical significance used in scientific research.
Wrapper methods train models on subsets of fields and evaluate the performance of those models to determine the best subset of features to select.
The most obvious method included in this subset is the Exhaustive Feature Selection method, where each combination of features is used to train a model. Each model’s performance is compared and the best performing subset is selected as the set of features for the actual learning task. This returns the best performing subset of features over all of the possible combinations.
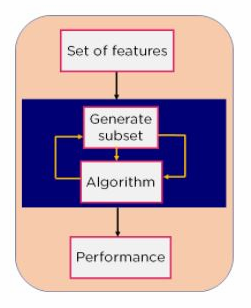
Intrinsic methods are similar to wrapper methods of feature selection in that they involve training a model. While wrapper methods do preliminary training of example models in order to extract statistical information intrinsic methods take place during the actual model training process.
Cassandra.Link
Cassandra.Link is a knowledge base that we created for all things Apache Cassandra. Our goal with Cassandra.Link was to not only fill the gap of Planet Cassandra but to bring the Cassandra community together. Feel free to reach out if you wish to collaborate with us on this project in any capacity.
We are a technology company that specializes in building business platforms. If you have any questions about the tools discussed in this post or about any of our services, feel free to send us an email!

